By Yin Nwe Ko
I INITIALLY began my academic journey with a strong focus on engineering because I found great satisfaction in seeing how my work could be applied to solve real-world problems. The tangible impact of engineering was gratifying, but I sought a way to leverage this knowledge to contribute to health improvements. My interest gradually shifted towards the biological applications of engineering, specifically in the study of otoacoustic emissions – the sounds our ears generate. This fascinating phenomenon is used to understand the functionality of the hearing system, which is particularly crucial for assessing hearing in infants or individuals with cognitive impairments who cannot effectively communicate their hearing issues. This objective method of evaluating hearing health intrigued me and motivated me to explore more objective tools and techniques for assessing human health overall.
This interest eventually led me to the field of voice science and voice disorders, areas closely related to the hearing system. Our hearing system is integral to voice perception, as it processes the sounds we hear when someone speaks. My research now encompasses both voice production and perception, utilizing my engineering background to develop the methodologies and tools essential for this work. By studying how we produce and perceive voice, I aim to enhance our understanding of these processes and contribute to the development of better diagnostic and therapeutic tools.
The connection between vocal production and perception is deeply rooted in the brain, which controls both systems. For instance, infants need to hear sounds to learn to produce them, highlighting the interplay between these systems during speech development. Despite this connection, the high-level processing of voice production and perception occurs in separate systems. Voice production primarily involves the phonatory system located in the larynx, controlled by over 20 muscles, along with additional muscles linked to the jaw, sternum, and other parts of the body. The respiratory system also plays a critical role, as we need to exhale to speak, while the articulatory system, including the mouth, shapes the sound.
On the other hand, the hearing system comprises distinct structures, such as the peripheral and central auditory systems. These systems process sound signals at various stages, with the brain handling the high-level processing. In my research, I am exploring how artificial intelligence can replicate this complex processing. By simulating the brain’s approach to sound processing, we aim to develop AI systems that can mimic human voice perception, enhancing our understanding and capabilities in this field.
When we talk about dysphonia, we refer to an abnormal quality of voice. For instance, a person with dysphonia might have a breathy voice that’s difficult to hear or a voice that’s frequently interrupted. This condition indicates a problem with the biomechanics or physics of voice production in the larynx or voice box. My research focuses on neurogenic voice disorders, which are particularly challenging to diagnose because their symptoms often resemble those of other disorders. Although the underlying mechanisms affecting the vocal folds or the larynx differ, these distinctions are hard to identify in a clinical setting. That is where our research and artificial intelligence (AI) come into play.
To diagnose these disorders more effectively, we utilize high-speed video technology to capture thousands of images of the vocal folds’ vibrations during speech. This method provides a wealth of data critical for understanding and differentiating these disorders. We then employ AI to analyze these images and extract significant features. AI’s capability to process vast datasets quickly allows us to identify subtle patterns and hidden features that are not discernible through manual inspection. This speed and precision are particularly valuable in clinical environments, where time is often limited.
Beyond diagnostics, AI has other significant applications in our research. Similar to facial recognition technology, which identifies facial features and emotions, AI can analyze high-speed videos of vocal folds to classify various tissue structures automatically. This process eliminates the need for manual image examination, making it feasible to analyze extensive datasets rapidly. We design AI tools to identify and track specific features within these videos, enabling us to study the movement and behaviour of different tissues comprehensively.
AI operates in two primary ways in our research. First, it captures and processes information that is visible but difficult to analyze manually due to the volume of data. Second, AI uncovers hidden information that aids in the differential diagnosis of voice disorders. For instance, AI can detect subtle variations in voice quality, such as breathiness or strain, which are challenging to identify otherwise.
One remarkable capability of AI is its ability to analyze temporal data – information spread across time. In just one minute of recording, we might have around 300,000 images. Instead of teaching AI-specific features to look for, we can provide it with raw data and let it perform a complex, trial-and-error analysis. Although we guide the AI in this process, it largely operates independently, extracting features and creating a comprehensive information map. This map highlights critical time intervals and specific voice qualities, such as breathiness or strain, enabling us to make more accurate diagnoses and understand the underlying issues more thoroughly.
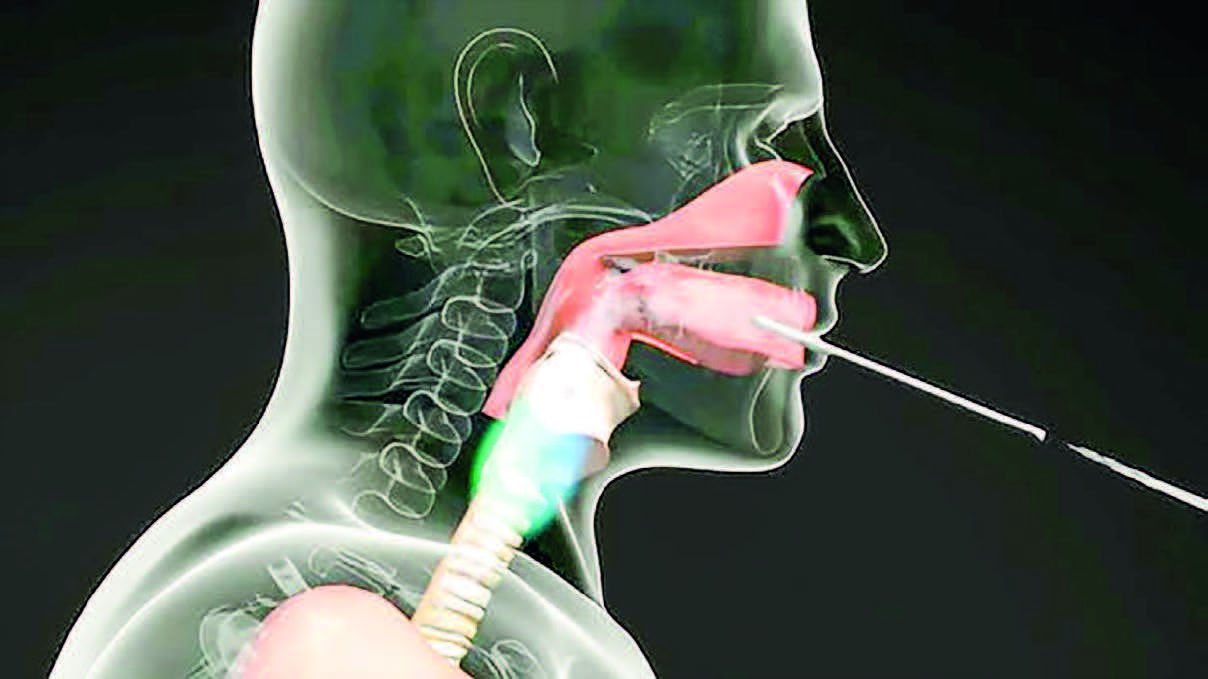
To record high-speed videos of vocal fold vibrations while someone is talking, we use two primary methods. The first method involves a rigid endoscope, which is a cylindrical device inserted through the mouth and positioned towards the back of the tongue. This endoscope is connected to a high-speed camera located outside the mouth. When the endoscope is in place, the person can produce vowels or perform a pitch glide, moving up and down in pitch. However, this method limits the range of speech the person can produce.
The second method employs a flexible scope connected to the high-speed camera, which is inserted through the nose to a position just above the vocal folds. This approach allows for a broader range of speech, enabling the person to speak various words, vowels, and consonants. We recently utilized this technique for data collection at the Mayo Clinic in Arizona. This method is particularly beneficial for studying task-specific voice disorders, where symptoms vary significantly based on what the person is saying. For instance, someone might be able to say “Aaaaah” without issue, but problems arise when they start speaking in sentences. This disorder, known as laryngeal dystonia, is rare and particularly interesting because it can affect specific activities like singing while leaving normal speech unaffected. We are currently studying a subject with this condition to gain a deeper understanding of the disorder.
Our ongoing research into laryngeal dystonia has yielded intriguing results. We are examining how the content of speech, specifically the transition between different vowels and consonants, affects the severity of symptoms. One notable observation is the significant variability in symptoms among individuals with the same disorder. Clinically, patients are often categorized similarly and receive the same treatment, typically Botox injections, based on the collective experience of laryngologists. However, we aim to understand these individual differences better to develop more personalized treatment approaches. By analyzing the variability in laryngeal behaviour during speech, we hope to determine if a uniform treatment approach is effective for all patients or if individualized treatments are necessary.
Our ultimate goal is to design tailored treatment plans that account for the unique characteristics of each patient’s condition. We are working to model voice production to answer critical questions about the effectiveness of treatments across different individuals. For example, we want to know if the same treatment will work for patients with overlapping symptoms. By addressing these questions, we aim to enhance the effectiveness of treatments for laryngeal dystonia and improve the overall quality of life for those affected by this disorder.
We are designing mechanical models to investigate how airflow from the lungs interacts with the vocal folds and how tissue movements generate sound. These models help us understand what happens if there is a disruption in these systems, how it manifests in a person’s voice, and how we might develop treatment strategies for such anomalies.
Regarding the singer’s dystonia, which affects only the singing voice, one hypothesis is that it could be an early indicator of a neurological disease. Voice production involves the precise coordination of the respiratory system and vocal fold vibrations. Any disorder affecting these systems, such as a neurological or mental health issue, will reflect in the voice. For instance, many research groups are exploring voice evaluation for diagnosing conditions like Parkinson’s disease.
In our lab, we aim to use voice analysis to assess depression and anxiety in patients. We are developing a tool that can evaluate an individual’s voice as a biomarker for various health issues. Voice production involves complex physiological processes, and any weakness in the muscles can affect the voice, although these changes may not be easily perceivable. Therefore, having objective tools to evaluate voice can reveal information that is not evident through simple listening or acoustic signals.
Artificial intelligence (AI) holds great potential for creating personalized models of a person’s voice by summarizing various measurements and information. For example, surgeons dealing with laryngeal cancer currently use extensive questionnaires to decide on treatment approaches. AI could streamline this process by providing summarized, relevant information based on the disorder’s pathophysiology. However, AI will likely not replace the nuanced decision-making of doctors, who rely on real experience to make informed choices.
Our research goal is to develop protocols that can be used clinically. We aim to understand the fundamentals of voice production and how various factors, such as mental health status or treatments like radiation therapy for laryngeal cancer, might affect it. Laryngeal cancer is of particular interest because it has one of the highest suicide rates among cancers, possibly due to its impact on the ability to communicate.
We strive to use our understanding of voice to improve clinical diagnoses and create accurate, individualized treatment approaches. Additionally, we are exploring the use of voice as a biomarker for other health issues. We have started data collection at Henry Ford Health and anticipate obtaining intriguing results from these projects soon. Our ultimate aim is to enhance the diagnostic and treatment capabilities for voice-related disorders and other health conditions reflected in the voice.
Reference:
The excerpt of the interview with Maryam Naghibolhosseini, the director of the Analysis of Voice and Hearing Laboratory at Michigan State University, and the editor-in-chief from American Scientist Magazine (July-August 2024 issue)


